← Back to Field Log
Progress
- ✓ Benchmark Dataset
- ✓ LangSmith Integration
- ✓ Regression Harness
- ◉ Automated Scorecards
- ○ CI Integration
- ○ Production Monitoring
Log Entry #7 · June 8
Integrated LangSmith tracing.
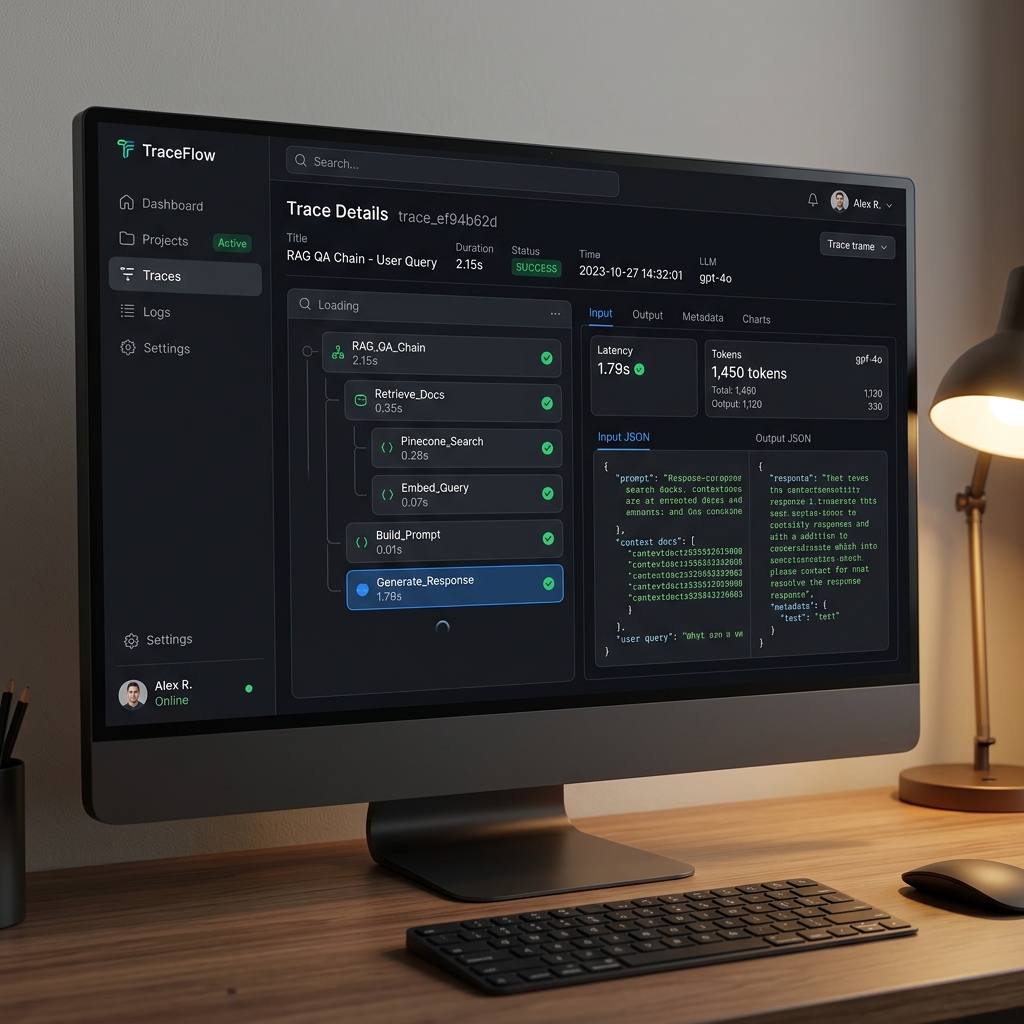
- Problem: Hallucinations slipped through manual testing.
- What we tried: Trace-based evaluation using LLM-as-a-judge.
- Result: Caught 2 regressions before merge.
- Next: Automated scorecards across the test suite.
Log Entry #6 · June 5
Attempted heuristic evaluator.
- Failure: False positives were too high. Regex matching against LLM output is too brittle.
- Decision: Abandoned approach. Rolling back to standard exact-match where possible, LLM-as-a-judge everywhere else.
Log Entry #5 · June 2
Baseline benchmark created.
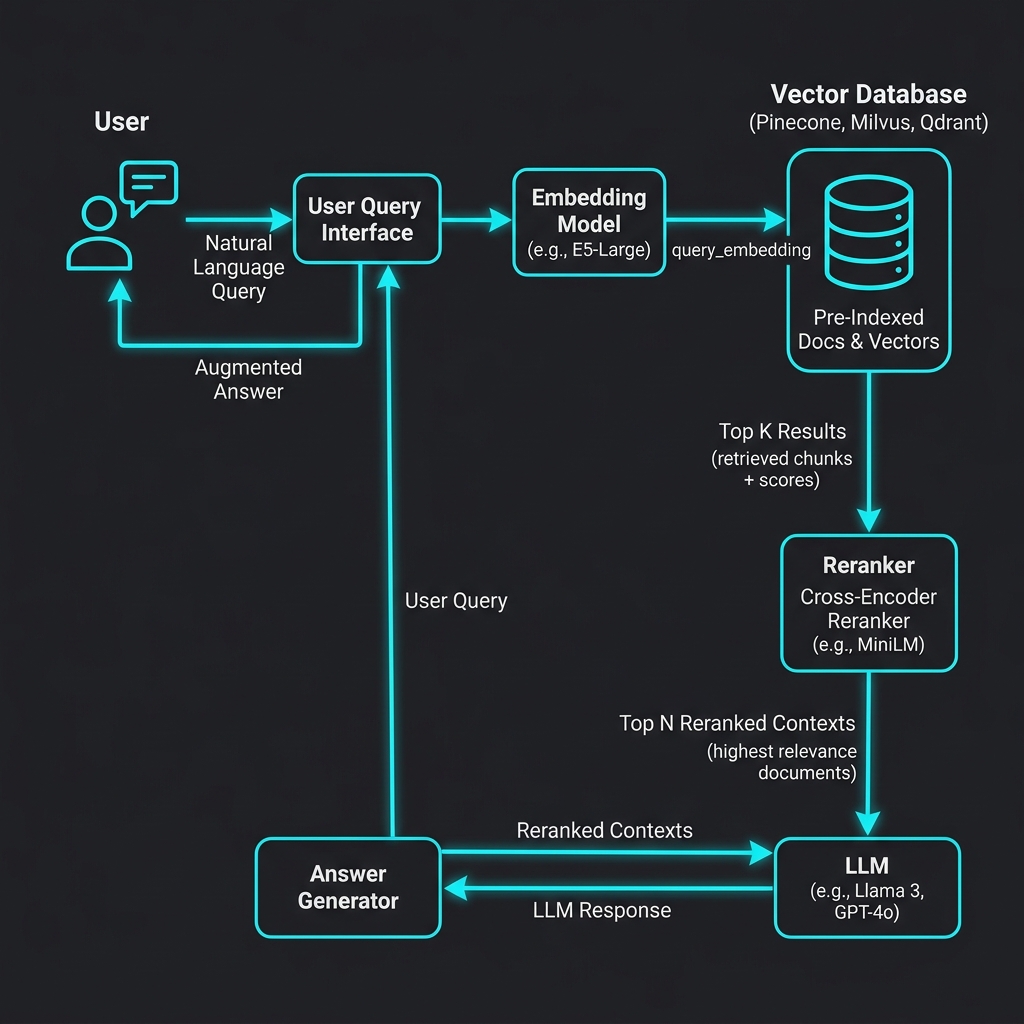
- Result: We now have a gold-standard dataset of 150 query-context pairs.
Learnings So Far
3 lessons from this build:
- Exact-match evaluators fail quickly. Human language varies too much to rely strictly on regex checks.
- LLM-as-a-judge works better than expected. Especially when constrained with a strict grading rubric and 5-shot examples.
- Tracing is mandatory before optimization. You can’t effectively drop latency if you don’t know which node in the graph is blocking.